Building a Toxic Comment Classifier for a Kaggle Competition
My journey through the Kaggle Toxic Comment Classification challenge, from data analysis to building GRU and TextCNN models with Keras.
This project is based on the Kaggle Competition: Toxic Comment Classification Challenge.
The challenge was to build a multi-headed model that’s capable of detecting different types of toxicity like threats, obscenity, insults, and identity-based hate. This was my first NLP Competition on Kaggle.
Exploratory Data Analysis
Disclaimer: The following content contains words that may be considered vulgar, profane, or offensive.
The dataset was made up of 8 columns: id, Comments, and 6 categories (toxic, severe_toxic, obscene, threat, insult, and identity_hate).
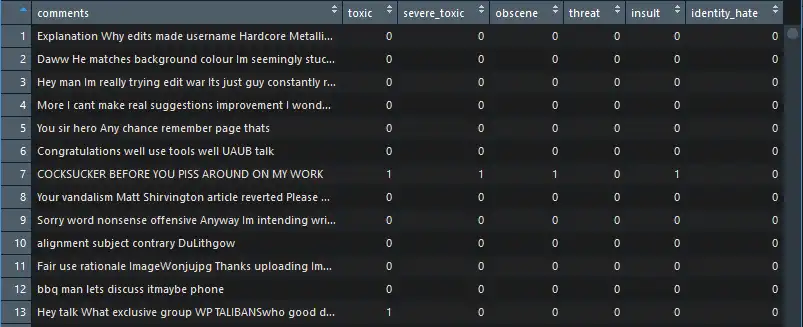
-
Dimensions of training set = 159571 x 8 and dimensions of Testing set = 153164 x 2
-
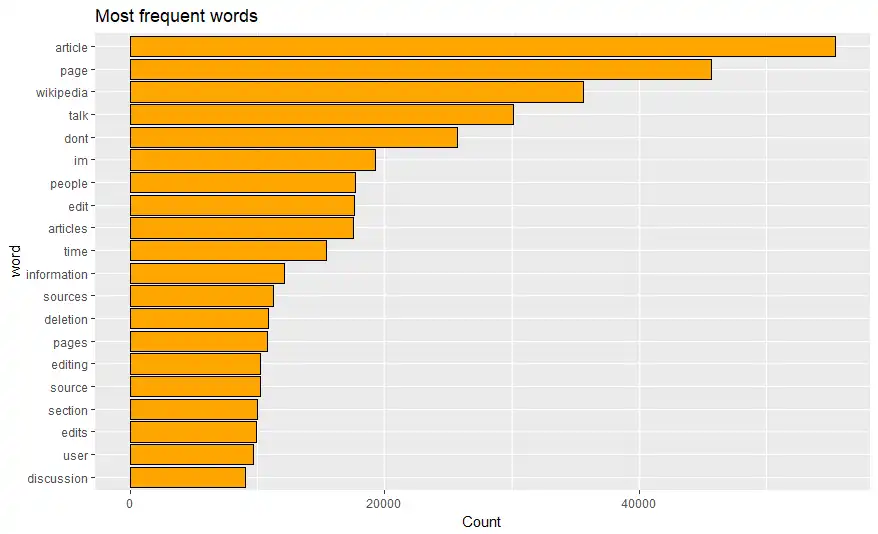
Most frequent words in training set are shown in bar graph
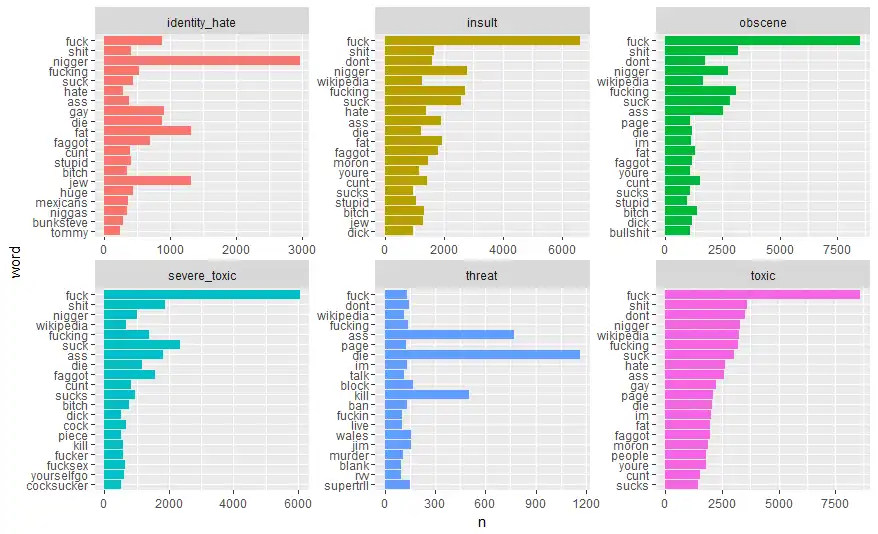
- Following graph shows most common words in each category.
Model
In the era of Deep learning, I decided to train neural networks for this task. Special types of neural networks called Recurrent Neural Networks (RNNs) are used to solve problems that exhibit the behavior of a time sequence.
Final models submitted to the competition were a GRU model and a TextCNN. An average of the two models scored an AUC of 0.9786 on the test data.
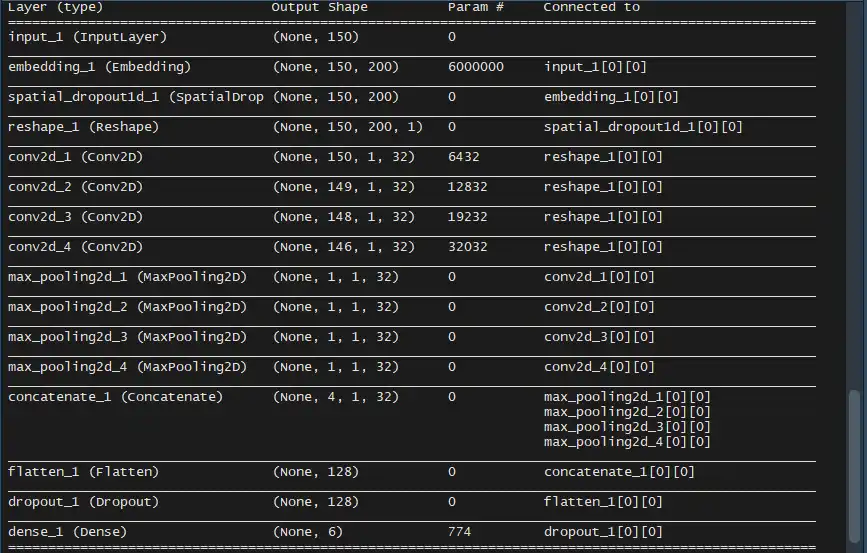
The following diagrams show the architecture of the GRU and TextCNN models.
- GRU
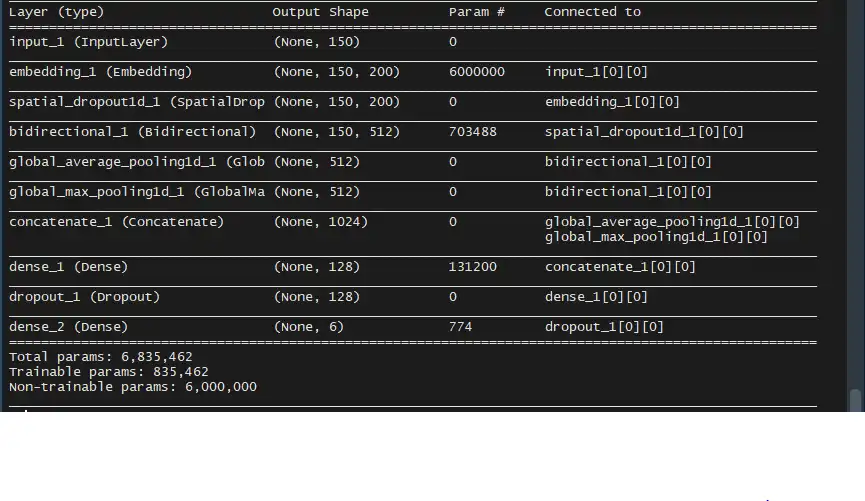
- TextCNN
Metric
AUC-ROC (Area under curve-receiver operating curve) was metric used for this problem. ROC curve is a plot of True positive rate vs False positive rate. True positive rate defines number of correct positive results among all positive samples, similarly false positive rate defines number of incorrect positive results among all negative samples. Diagonal represents 50% probability; it is no better than random chance. Points above diagonal represent good classification result that is better than random.
Long-Short Term Memory Cells
Long-Short Term Memory(LSTM) are building units from layers of Recurrent neural networks. It is composed of Cell State, Input Gate, Output Gate and Forget gate. Cell state carries information from one cell to another. Forget gate is made up of sigmoid layer. It outputs the value between 0-1 to determine how much information to store from previous cell state. Input gate determines what new information to store in cell state. It is made up of two layers:
- sigmoid layer: This layer determines which value will update from old cell state
- tanh layer: This layer creates candidate values to add to cell state
The new cell state is calculated as, old cell state x forget gate + input gate where input gate = sigmoid layer x tanh layer. Finally in output layer, sigmoid layer decides which part of cell state is going to output. Then cell state is passed through tanh layer to push the vales between (-1,1) and then multplied with output of sigmoid gate.
Gated Recurrent Units(GRU)
Gated Recurrent Units are based on LSTM(Long-Short Term Memory) cells. The difference between LSTM and GRU are as follows:
- Input and Output gates are combined into update gate
- Cell state and Hidden state are merged together
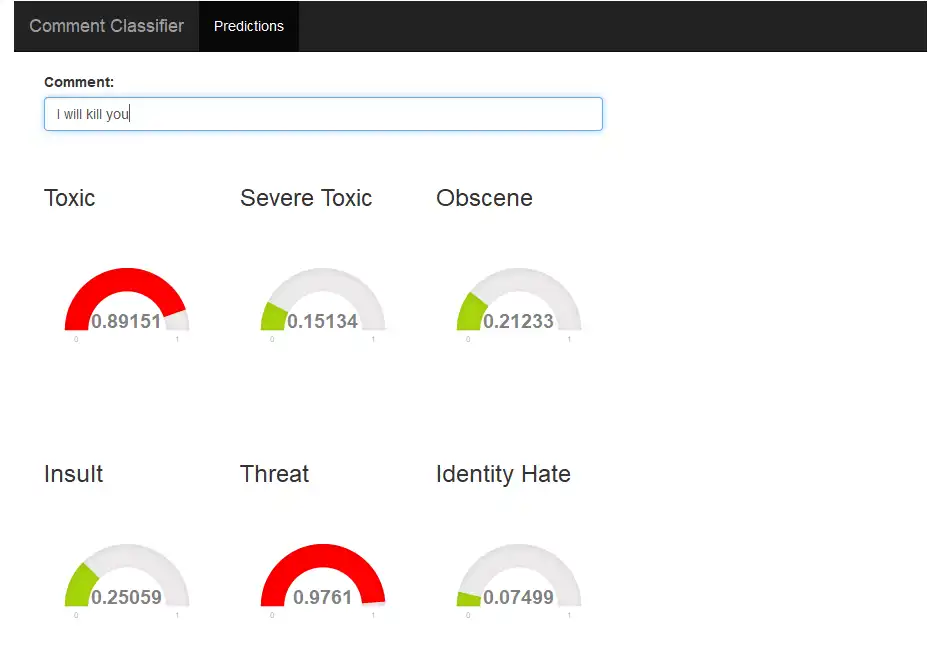
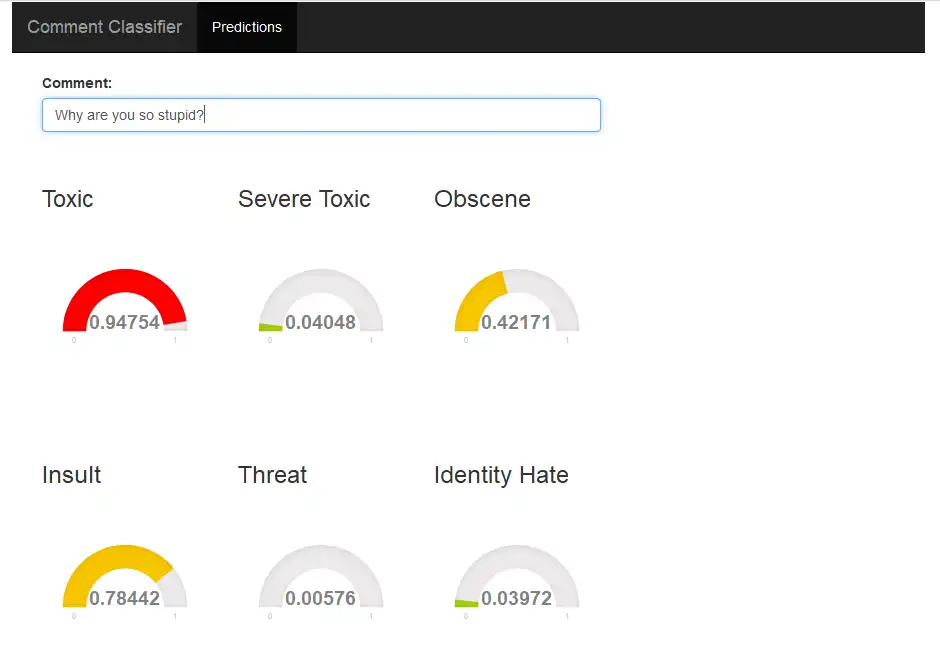
Shiny App
I made an application that shows how toxic a sentence is in real-time. Following are a few screenshots of the application.
Conclusion
Following are the concepts related to NLP that I learned during this competiton.
- weighted Tfidf
- TermDocumentMatrix/DocumentTermMatrix
- WordEmbeddings
- RNN: GRU and LSTM
- Implementation of GRU and LSTM with hyperparameter tuning and cross-validation
- Implementation of CNN for text Classification
- Metric: AUC-ROC
- Always trust your cv score rather than public leaderboard score
There was lot of confusion regarding overfitting on leaderboard due lots of blends of blends models. Hence I decided to stick with my own models rather than blends of blends and thought this would help me when final results come out. But unfortunately the blends were not overfitted and I went down the leaderboard. It was nice to explore the field which was completely new to me. Moving on to next competetion…
Cite this post
APA
Mrugank Akarte. (2018). Building a Toxic Comment Classifier for a Kaggle Competition. Retrieved from https://mrugankakarte.github.io/blog/toxic-comments-classifier/
BibTeX
@misc{mrugankakarte2018,
author = {Mrugank Akarte},
title = {Building a Toxic Comment Classifier for a Kaggle Competition},
year = {2018},
url = {https://mrugankakarte.github.io/blog/toxic-comments-classifier/},
}