An Introduction to Reinforcement Learning
A foundational guide to Reinforcement Learning, covering key concepts like policies, rewards, value functions, and Markov Decision Processes (MDP).
Introduction
Reinforcement learning is a type of machine learning problem which is solved using the past experiences and interactions of the agent with the world. In other words, Reinforcement learning is mappings of situations with the available actions to maximize a numerical reward signal. Usually rewards are positive if the action taken is desirable and negative if the action is undesirable. The agent is never told which action to take or which action is optimal for a given situation, but instead it must discover on its own which actions to take that would yield maximum reward. In many cases the action taken for a given situation may affect not only immediate reward but also the next situation and may have consequences on future rewards. These characteristics of trial and error search and delayed rewards are distinguishing features of reinforcement learning.
Reinforcement learning is different from supervised and unsupervised learning. Supervised learning is learning for a training set of known and labelled examples. Each example contains a set of features with its appropriate label. Reinforcement learning is an interactive problem in which it is often impossible to obtain the examples of desired behaviour that are both correct and representative of all situation for which the agent must act. Unsupervised learning is about finding hidden structure in an unlabelled dataset. Reinforcement learning is about maximizing the reward by taking actions in an unseen situation. Although finding hidden structure in data will be useful for learning but it does not address its the objective. Hence, Reinforcement is considered different from supervised and unsupervised machine learning.
The problem of reinforcement learning is formalized as a fully observed or partial Markov Decision Process (MDP). We will discuss MDP subsequently, first let’s discuss the basic terminologies used in reinforcement learning and one the most important challenges faced, trade-off between exploration and exploitation. To obtain a positive reward, the agent has to take right action for a given situation. Since the agent is never told what the optimal action is, the agent must take some action and experience the consequences. It must try all the actions available and then select the action which gives maximum reward. In this process the agent has to exploit what he already knows from the previous actions taken and explore all the possible options to make a better action selection in the future. The dilemma here is that neither exploration nor exploitation can be pursued exclusively without failing at task. The agent must try a variety of actions and progressively favour those which appear to be best.
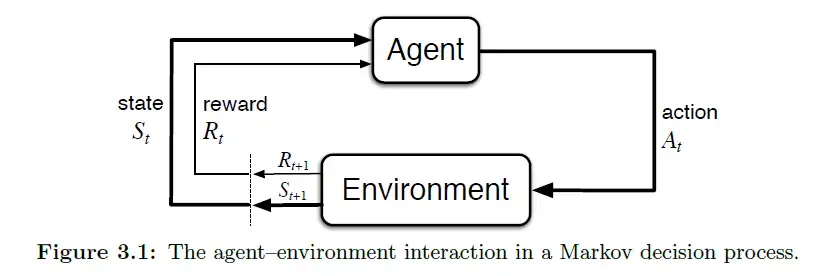
Reinforcement learning system
A reinforcement learning system consists of a policy, a reward signal, a value function, and optionally a model of the environment.
- Policy defines what action to take at any given situation (hereafter referred as state).
- Reward signal defines the goal of a reinforcement learning problem.
- Value function defines what is good in the long run. It gives an estimate of the total amount of reward that an agent can accumulate over the future starting from that state.
- Model is something that can mimic an environment. Reinforcement learning problems which use models are known as model-based methods.
Markov Decision Process
Markov Decision Process (MDP) provide a framework to model decision making process where outcomes are partly random and partly under the control of decision maker. The learner or decision maker is called an agent. The agent interacts with the environment which comprises of everything except the agent.
The process flow in a MDP is as follows:
- We get the current state from the environment
- Agent takes action from all possible actions for the given state
- Environment reacts to the action taken by agent and present the reward and next state
- We modify the agents policy based on the rewards received
- Agent again acts for the new state using the modified policy
This process continues until the task is accomplished.
Policy and Value Functions
Value functions are functions that estimate “how good” it is for an agent to be in a given state. This is defined in terms of future rewards that can be expected. Value functions are defined with respect to particular ways of acting called policies.
A policy function can be defined as a mapping between the state and the probability of selecting each possible action. Mathematically value function is defined as follows:
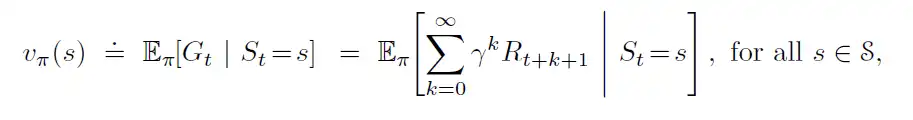
where, Eπ[.] denotes expected value of random variable given that agent follows the policy π and t is any time-step. This is also known as state-value function for policy π.
Similarly action-value function is defined as value of taking action a, given state s under policy π.
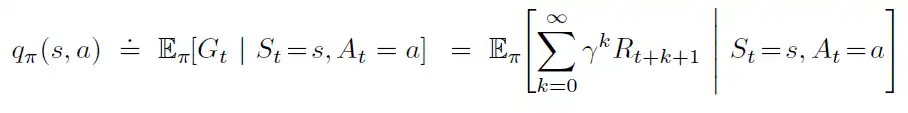
Value-based reinforcement learning
In value-based learning, the objective is to optimize the value function. The agent will use this value function to select the action for a given state. The agent takes the action with the biggest value.
Policy-based reinforcement learning
In policy-based reinforcement learning, the objective is to optimize the policy function π(s). The policy determines the probability for each possible action given a state, and an action from this probability distribution is selected.
In the next article, we will discuss the value-based methods called Q-learning and Deep Q-Learning.
PS: Most of the details are from Barto and Sutton, Reinforcement Book, Second Edition 2018. This post is my understanding of the topics from the book.
Cite this post
APA
Mrugank Akarte. (2019). An Introduction to Reinforcement Learning. Retrieved from https://mrugankakarte.github.io/blog/reinforcement-learning/
BibTeX
@misc{mrugankakarte2019,
author = {Mrugank Akarte},
title = {An Introduction to Reinforcement Learning},
year = {2019},
url = {https://mrugankakarte.github.io/blog/reinforcement-learning/},
}